One of our databases went over the fritz yesterday. We regurarly receive a request from the functional administrators to kill a session (batch-user) in the database. Often the session doesn’t end quick enough to the admin’s likings.
At noon, we were asked to kill a session, shortly thereafter we were asked to kill -9 the session on the OS (solaris 10, whole root container). The exact is unknown at this time when the command was given.
At 13:20 we received a phone call that the database wasn’t responding at all. One look in OEM learned the following:
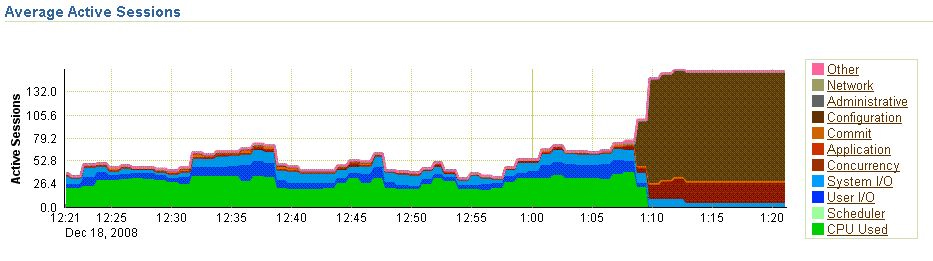
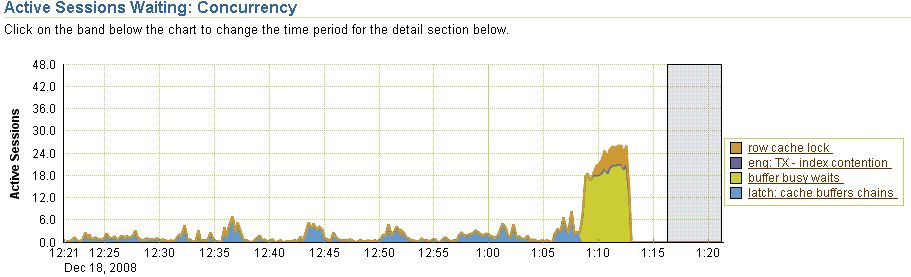
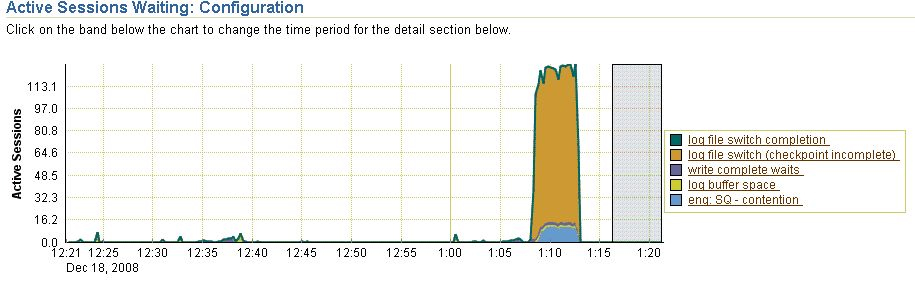
Top showed that machine CPU was 96.8% idle. The PMON process took 2.8% of the CPU. Below an excerpts of the tracefile:
*** 2008-12-12 14:25:19.155 *** SERVICE NAME:(SYS$BACKGROUND) 2008-12-12 14:25:19.151 *** SESSION ID:(93.1) 2008-12-12 14:25:19.151 *** 2008-12-12 14:25:19.156 Doing block recovery for file 40 block 269667 Block header before block recovery: buffer tsn: 41 rdba: 0x0a041d63 (40/269667) scn: 0x000a.deb673f5 seq: 0x08 flg: 0x04 tail: 0x73f50608 frmt: 0x02 chkval: 0x53cd type: 0x06=trans data Doing block recovery for file 40 block 269667 Block header before block recovery: buffer tsn: 41 rdba: 0x0a041d63 (40/269667) scn: 0x000a.deb673f5 seq: 0x08 flg: 0x04 tail: 0x73f50608 frmt: 0x02 chkval: 0x53cd type: 0x06=trans data Doing block recovery for file 40 block 269667 Block header before block recovery: buffer tsn: 41 rdba: 0x0a041d63 (40/269667) scn: 0x000a.deb673f5 seq: 0x08 flg: 0x04 tail: 0x73f50608 frmt: 0x02 chkval: 0x53cd type: 0x06=trans data Doing block recovery for file 40 block 269667 Block header before block recovery: buffer tsn: 41 rdba: 0x0a041d63 (40/269667) scn: 0x000a.deb673f5 seq: 0x08 flg: 0x04 tail: 0x73f50608 frmt: 0x02 chkval: 0x53cd type: 0x06=trans data ...
It appeared that at 12:17 a corruption occurred in the online redo logs. We suspect that the corruption occurred because of the kill -9 and prop. a rare oracle bug. What exactly went on inside the database between 12:17 and 13:13, we don’t know.
Anybody any ideas ..?